A deep insight into Functional Programming
What is Functional Programming
In computer science, functional programming is a programming paradigm—a style of building the structure and elements of computer programs—that treats computation as the evaluation of mathematical functions and avoids changing-state and mutable data. It is a declarative programming paradigm, which means programming is done with expressions or declarations instead of statements. In functional code, the output value of a function depends only on the arguments that are passed to the function, so calling a function f twice with the same value for an argument x produces the same result f(x) each time; this is in contrast to procedures depending on a local or global state, which may produce different results at different times when called with the same arguments but a different program state. Eliminating side effects, i.e., changes in state that do not depend on the function inputs, can make it much easier to understand and predict the behavior of a program, which is one of the key motivations for the development of functional programming.
History
Lambda calculus provides a theoretical framework for describing functions and their evaluation. It is a mathematical abstraction rather than a programming language—but it forms the basis of almost all current functional programming languages. An equivalent theoretical formulation, combinatory logic, is commonly perceived as more abstract than lambda calculus and preceded it in invention. Combinatory logic and lambda calculus were both originally developed to achieve a clearer approach to the foundations of mathematics.
An early functional-flavored language was Lisp, developed in the late 1950s for the IBM 700/7000 series scientific computers by John McCarthy while at Massachusetts Institute of Technology (MIT). Lisp first introduced many paradigmatic features of functional programming, though early Lisps were multi-paradigm languages, and incorporated support for numerous programming styles as new paradigms evolved. Later dialects, such as Scheme and Clojure, and offshoots such as Dylan and Julia, sought to simplify and rationalise Lisp around a cleanly functional core, while Common Lisp was designed to preserve and update the paradigmatic features of the numerous older dialects it replaced.
Information Processing Language (IPL) is sometimes cited as the first computer-based functional programming language. It is an assembly-style language for manipulating lists of symbols. It does have a notion of generator, which amounts to a function that accepts a function as an argument, and, since it is an assembly-level language, code can be data, so IPL can be regarded as having higher-order functions. However, it relies heavily on mutating list structure and similar imperative features.
Kenneth E. Iverson developed APL in the early 1960s, described in his 1962 book A Programming Language. APL was the primary influence on John Backus’s FP. In the early 1990s, Iverson and Roger Hui created J. In the mid-1990s, Arthur Whitney, who had previously worked with Iverson, created K, which is used commercially in financial industries along with its descendant Q.
John Backus presented FP in his 1977 Turing Award lecture “Can Programming Be Liberated From the von Neumann Style? A Functional Style and its Algebra of Programs”. He defines functional programs as being built up in a hierarchical way by means of “combining forms” that allow an “algebra of programs”; in modern language, this means that functional programs follow the principle of compositionality[citation needed]. Backus’s paper popularized research into functional programming, though it emphasized function-level programming rather than the lambda-calculus style now associated with functional programming.
In the 1970s, ML was created by Robin Milner at the University of Edinburgh, and David Turner initially developed the language SASL at the University of St Andrews and later the language Miranda at the University of Kent. Also in Edinburgh in the 1970s, Burstall and Darlington developed the functional language NPL. NPL was based on Kleene Recursion Equations and was first introduced in their work on program transformation. Burstall, MacQueen and Sannella then incorporated the polymorphic type checking from ML to produce the language Hope. ML eventually developed into several dialects, the most common of which are now OCaml and Standard ML. Meanwhile, the development of Scheme, a simple lexically scoped and (impurely) functional dialect of Lisp, as described in the influential Lambda Papers and the classic 1985 textbook Structure and Interpretation of Computer Programs, brought awareness of the power of functional programming to the wider programming-languages community.
In the 1980s, Per Martin-Löf developed intuitionistic type theory (also called constructive type theory), which associated functional programs with constructive proofs of arbitrarily complex mathematical propositions expressed as dependent types. This led to powerful new approaches to interactive theorem proving and has influenced the development of many subsequent functional programming languages.
The Haskell language began with a consensus in 1987 to form an open standard for functional programming research; implementation releases have been ongoing since 1990.

Comparison to Imperative Programming
Functional programming is very different from imperative programming. The most significant differences stem from the fact that functional programming avoids side effects, which are used in imperative programming to implement state and I/O. Pure functional programming completely prevents side-effects and provides referential transparency.
Higher-order functions are rarely used in older imperative programming. A traditional imperative program might use a loop to traverse and modify a list. A functional program, on the other hand, would probably use a higher-order “map” function that takes a function and a list, generating and returning a new list by applying the function to each list item.
Simulating state
There are tasks (for example, maintaining a bank account balance) that often seem most naturally implemented with state. Pure functional programming performs these tasks, and I/O tasks such as accepting user input and printing to the screen, in a different way.
The pure functional programming language Haskell implements them using monads, derived from category theory. Monads offer a way to abstract certain types of computational patterns, including (but not limited to) modeling of computations with mutable state (and other side effects such as I/O) in an imperative manner without losing purity. While existing monads may be easy to apply in a program, given appropriate templates and examples, many students find them difficult to understand conceptually, e.g., when asked to define new monads (which is sometimes needed for certain types of libraries).
Another way that functional languages can simulate state is by passing around a data structure that represents the current state as a parameter to function calls. On each function call, a copy of this data structure is created with whatever differences are the result of the function. This is referred to as ‘state-passing style’.
Impure functional languages usually include a more direct method of managing mutable state. Clojure, for example, uses managed references that can be updated by applying pure functions to the current state. This kind of approach enables mutability while still promoting the use of pure functions as the preferred way to express computations.
Alternative methods such as Hoare logic and uniqueness have been developed to track side effects in programs. Some modern research languages use effect systems to make the presence of side effects explicit.
Efficiency issues
Functional programming languages are typically less efficient in their use of CPU and memory than imperative languages such as C and Pascal. This is related to the fact that some mutable data structures like arrays have a very straightforward implementation using present hardware (which is a highly evolved Turing machine). Flat arrays may be accessed very efficiently with deeply pipelined CPUs, prefetched efficiently through caches (with no complex pointer chasing), or handled with SIMD instructions. It is also not easy to create their equally efficient general-purpose immutable counterparts. For purely functional languages, the worst-case slowdown is logarithmic in the number of memory cells used, because mutable memory can be represented by a purely functional data structure with logarithmic access time (such as a balanced tree). However, such slowdowns are not universal. For programs that perform intensive numerical computations, functional languages such as OCaml and Clean are only slightly slower than C according to The Computer Language Benchmarks Game. For programs that handle large matrices and multidimensional databases, array functional languages (such as J and K) were designed with speed optimizations.
Immutability of data can in many cases lead to execution efficiency by allowing the compiler to make assumptions that are unsafe in an imperative language, thus increasing opportunities for inline expansion.
Lazy evaluation may also speed up the program, even asymptotically, whereas it may slow it down at most by a constant factor (however, it may introduce memory leaks if used improperly). Launchbury 1993 discusses theoretical issues related to memory leaks from lazy evaluation, and O’Sullivan et al. 2008 give some practical advice for analyzing and fixing them. However, the most general implementations of lazy evaluation making extensive use of dereferenced code and data perform poorly on modern processors with deep pipelines and multi-level caches (where a cache miss may cost hundreds of cycles)[citation needed].
Coding Styles
Imperative programs have the environment and a sequence of steps manipulating the environment. Functional programs have an expression that is successively substituted until it reaches normal form. An example illustrates this with different solutions to the same programming goal (calculating Fibonacci numbers).
Python
- Iterative
def fibonacci(n, first=0, second=1):
while n != 0:
print(first) # side-effect
n, first, second = n - 1, second, first + second # assignment
fibonacci(10)
- Functional expression style
fibonacci = (lambda n, first=0, second=1:
"" if n == 0 else
str(first) + "\n" + fibonacci(n - 1, second, first + second))
print(fibonacci(10), end="")
Clojure
(defn fib
[n]
(loop [a 0 b 1 i n]
(if (zero? i)
a
(recur b (+ a b) (dec i)))))
Haskell
fibonacci_aux = \n first second->
if n == 0 then "" else
show first ++ "\n" ++ fibonacci_aux (n - 1) second (first + second)
fibonacci = \n-> fibonacci_aux n 0 1
main = putStr (fibonacci 10)
Declarative vs Imperative
Functional programming is a declarative paradigm, meaning that the program logic is expressed without explicitly describing the flow control.
Imperative programs spend lines of code describing the specific steps used to achieve the desired results — the flow control: How to do things.
Declarative programs abstract the flow control process, and instead spend lines of code describing the data flow: What to do. The how gets abstracted away.
For example, this imperative mapping takes an array of numbers and returns a new array with each number multiplied by 2:
const doubleMap = numbers => {
const doubled = [];
for (let i = 0; i < numbers.length; i++) {
doubled.push(numbers[i] * 2);
}
return doubled;
};
console.log(doubleMap([2, 3, 4])); // [4, 6, 8]
This declarative mapping does the same thing, but abstracts the flow control away using the functional Array.prototype.map() utility, which allows you to more clearly express the flow of data:
const doubleMap = numbers => numbers.map(n => n * 2);
console.log(doubleMap([2, 3, 4])); // [4, 6, 8]
Imperative code frequently utilizes statements. A statement is a piece of code which performs some action. Examples of commonly used statements include for, if, switch, throw, etc…
Declarative code relies more on expressions. An expression is a piece of code which evaluates to some value. Expressions are usually some combination of function calls, values, and operators which are evaluated to produce the resulting value.
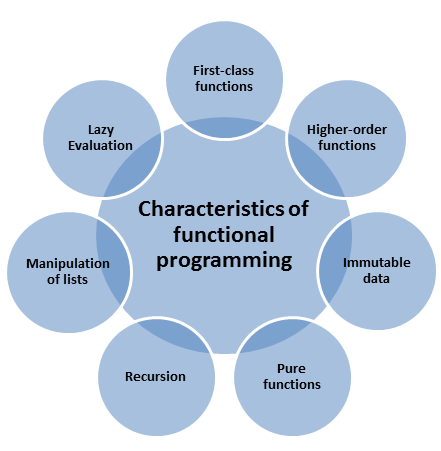
Characteristics
Functional programming favors:
- Pure functions instead of shared state & side effects
- Immutability over mutable data
- Function composition over imperative flow control
- Lots of generic, reusable utilities that use higher order functions to act on many data types instead of methods that only operate on their colocated data
- Declarative rather than imperative code (what to do, rather than how to do it)
- Expressions over statements
- Containers & higher order functions over ad-hoc polymorphism
Functional Programming in C++
Functional programming is becoming a required skill for all programmers, and for good reason. The functional style of programming lets you write more concise code which tends to have fewer bugs. It allows you to decompose your programs into smaller, highly reusable components, without putting conceptual limits on how the software should be modularized. FP makes software development easier and software more correct and robust. These techniques can be used as a complement to those from other programming paradigms, for example OOP, which makes FP a great fit for C++ as the most popular multi-paradigm language.
Higher order functions
Functions you can pass around and return, allowing fine grained reuse, currying, composition.
C++ std::function class or functions as template arguments allow this.
Closures
Functions that capture data when created, and keep it available to use when the function is run later.
C++ 11 lambdas allow this and have been widely discussed, as expected as they are one of the most exciting features in C++ 11. These do add a lot of flexibility and simplicity to C++ compared to previous library-only approaches.
Immutable data
const in C++ already allows this. Many functional languages allow mutable data to make interfacing with other languages and the external environment (UI, db, networks) so mixing mutable and immutable data is not alien, and const puts C++ in a better position compared to most other nearly-functional languages, with the compiler able to enforce at least some of this.
The use of immutable data to ease concurrent code has already been widely discussed (e.g. Sutter’s Mill GotW 6a) and again const puts C++ ahead of the pack as the compiler the helps make your code more thread safe. It only helps, it can’t stop you making every member-function const and marking all member-data with the mutable keyword without any locks. But most popular languages have no concept of immutable at all, and for years other developers have treated const in C++ as an old-fashioned restriction like checked exceptions. Well, the joke’s on the other foot now.
Immutable collections
The list-based immutable collections in most pure functional languages are often said to require garbage collection, although I wonder if they may be possible with C++ move semantics or certainly shared_ptr though admittedly with more overhead.
But I don’t think such collections are required for nearly-functional languages, they are only one way to support the algorithms that apply to the data.
Lazy Evaluation
Lazy Evaluation is mostly used to only process as much of a set of data as required, and in functional languages list-based immutable collections and higher-order functions are used to great effect.
Some form of iteration over collections while applying multiple functions together is required. Each data item is pulled through the series of functions one at time without needing to store the whole collection at each intermediate steps. But .Net LINQ, Scala collections and Java 8 streams show a different approach that works well, and which can also be parallelized.
C++ could easily follow this approach but C++ iterators currently make this hard. Passing a data-set around as separate begin and end parameters make code verbose and make it hard to chain calls together in a natural way. But boost::range may make this feasible, especially Range Adapters. This gives a nice syntax to chain functions together and may give a natural way to separate non-modifying functions from modifying functions.
Tail recursion
This is the elephant in the room of any serious discussion about functional languages, or at least any discussion with proponents of functional languages. But while important for processing and navigating the immutable collections that give pure functional languages much of their power, I don’t think it’s as all-important as it seems. A lot of recursion is actually hidden in higher level functions. Map, reduce etc. iterate over a container by using recursion over an immutable container. For this tail recursion is essential as the container is unbounded so the recursion is unbounded. But if map, reduce, … hide how the iteration is done, then it doesn’t have to be done by recursion. It can be simple iteration, or split across many threads.
There are algorithms that are more natural with recursion and these are used commonly in functional languages. But many of these actually have sharply limited depth requirements. Recursion over a visibly recursive data structure e.g. a binary tree, is generally limited by the depth of the tree. Recursion from repeatedly dividing the problem space is likewise is limited to log2 n or limited by how accurate the result needs to be.